

CS336: Lecture 01 - Introduction
 Bill
Bill CS336: Language Models From Scratch
#CS336
#LLM
Current Landscape of Language Models
Pre-neural (before 2010s)
- Language model to measure the entropy of English Shannon 1950
- 香农(Claude Shannon)的开创性工作,利用人类受试者对下一个字母的预测实验,首次量化了英语文本的信息熵和冗余度,奠定了自然语言统计建模的基础。
- Lots of work on n-gram language models (for machine translation, speech recognition) Brants+ 2007
- 谷歌团队在机器翻译中大规模应用N-gram语言模型的工作,展示了海量数据(2万亿词)对提升模型性能的巨大作用,是统计语言模型时代的代表作。
Neural ingredients (2010s)
- First neural language model Bengio+ 2003
- Yoshua Bengio等人提出的神经概率语言模型(NPLM),首次将神经网络用于语言建模,并引入了词向量(Word Embeddings)的概念,解决了传统N-gram的数据稀疏问题。
- Sequence-to-sequence modeling (for machine translation) Sutskever+ 2014
- 提出了Seq2Seq架构(Encoder-Decoder),使用LSTM处理变长输入和输出序列,在机器翻译任务上取得了突破性进展,是现代生成式模型的雏形。
- Adam optimizer Kingma+ 2014
- 提出了Adam优化算法,结合了动量法和自适应学习率的优点,因其高效和稳健性,成为后来训练大规模深度学习模型(包括LLM)的标准优化器。
- Attention mechanism (for machine translation) Bahdanau+ 2014
- 在机器翻译中首次引入注意力机制(Attention),允许模型在解码时动态“关注”源句子的不同部分,解决了长句子信息丢失的问题。
- Transformer architecture (for machine translation) Vaswani+ 2017
- 提出了完全基于注意力机制的Transformer架构,抛弃了循环神经网络(RNN),极大地提升了并行训练效率和长距离依赖的建模能力,是所有现代LLM的基石。
- Mixture of experts Shazeer+ 2017
- 提出了稀疏门控的混合专家(MoE)层,允许模型在极大规模参数下仅激活部分网络,从而在保持计算成本可控的同时大幅提升模型容量。
- Model parallelism Huang+ 2018Rajbhandari+ 2019Shoeybi+ 2019
- 这一系列工作(如GPipe, ZeRO, Megatron-LM)解决了单卡显存限制,开发了流水线并行、张量并行和优化器状态切片等技术,使得训练十亿甚至万亿参数的超大模型成为可能。
Early foundation models (late 2010s)
- ELMo: pretraining with LSTMs, fine-tuning helps tasks Peters+ 2018
- 使用双向LSTM进行预训练,生成的深层上下文词向量(Contextualized Word Embeddings)在多个NLP任务上显著优于静态词向量,开启了预训练-微调范式。
- BERT: pretraining with Transformer, fine-tuning helps tasks Devlin+ 2018
- 引入了双向Transformer编码器和掩码语言模型(MLM)预训练任务,在理解类任务上取得了SOTA效果,确立了“预训练+微调”作为NLP的主流范式。
- Google’s T5 (11B): cast everything as text-to-text Raffel+ 2019
- 提出了“Text-to-Text”的统一框架,将翻译、分类、摘要等所有NLP任务都转换为文本生成任务,并发布了C4数据集和T5模型。
Embracing scaling, more closed
- OpenAI’s GPT-2 (1.5B): fluent text, first signs of zero-shot, staged release Radford+ 2019
- 证明了在大规模数据集上训练的语言模型在零样本(Zero-shot)设置下具备惊人的多任务迁移能力,生成的文本流畅度极高。
- Scaling laws: provide hope / predictability for scaling Kaplan+ 2020
- 系统研究了模型性能与算力、数据量、参数量之间的幂律关系(Power Laws),为后续大模型的资源投入和性能预期提供了理论指导。
- OpenAI’s GPT-3 (175B): in-context learning, closed Brown+ 2020
- 将参数量扩展到1750亿,展示了强大的上下文学习(In-context Learning)能力,即无需微调,仅通过提示(Prompt)即可完成复杂任务。
- Google’s PaLM (540B): massive scale, undertrained Chowdhery+ 2022
- 基于Pathways系统训练的5400亿参数稠密模型,展示了随着规模扩大而涌现出的推理和逻辑能力(如思维链CoT),但相对于其参数量,训练数据量略显不足。
- DeepMind’s Chinchilla (70B): compute-optimal scaling laws Hoffmann+ 2022
- 修正了Scaling Laws,提出在给定计算预算下,模型大小和训练数据量应等比例缩放,证明了更小但训练更充分的模型(70B)可以击败更大的模型(如Gopher 280B)。
Open models
- EleutherAI’s open datasets (The Pile) and models (GPT-J) Gao+ 2020Wang+ 2021
- The Pile是一个高质量的大规模开源文本数据集;GPT-J是基于该数据训练的60亿参数模型,证明了开源社区有能力复现GPT-3级别的效果。
- Meta’s OPT (175B): GPT-3 replication, lots of hardware issues Zhang+ 2022
- Meta复现并开源了与GPT-3同等规模的175B模型,详细记录了训练过程中的工程挑战和硬件不稳定性,旨在推动大模型研究的透明化。
- Hugging Face / BigScience’s BLOOM: focused on data sourcing Workshop+ 2022
- 由全球1000多名研究人员协作完成的176B多语言大模型,特别强调数据的多样性、透明度和多语言支持(涵盖46种语言和13种编程语言)。
- Meta’s Llama models Touvron+ 2023Touvron+ 2023Dubey+ 2024
- Llama系列通过使用更多高质量数据训练更小参数的模型,重新定义了开源模型的性能标准;Llama 3更是将性能推向了前沿,支持多语言和长上下文。
- Alibaba’s Qwen models Qwen+ 2024
- 通义千问(Qwen)系列,在中英双语及代码能力上表现优异,技术报告详细介绍了其预训练、SFT及RLHF的技术细节。
- DeepSeek’s models DeepSeek-AI+ 2024DeepSeek-AI+ 2024DeepSeek-AI+ 2024
- DeepSeek系列(LLM, V2, V3)以极高的性价比著称,创新性地改进了MoE架构和注意力机制(MLA),大幅降低了训练和推理成本,同时保持顶尖性能。
- AI2’s OLMo 2 Groeneveld+ 2024OLMo+ 2024
- OLMo系列不仅开源权重,还开源了完整的训练数据、代码和中间检查点,致力于揭开LLM训练的“黑盒”,促进大模型科学的开放研究。
Levels of openness
- Closed models (e.g., GPT-4o): API access only OpenAI+ 2023
- 仅提供API接口,不公开模型权重、架构细节或训练数据,代表了商业化闭源模型的路线。
- Open-weight models (e.g., DeepSeek): weights available, paper with architecture details, some training details, no data details DeepSeek-AI+ 2024
- 公开模型权重供下载使用,发布技术报告说明架构和部分训练方法,但通常不公开具体的训练数据集。
- Open-source models (e.g., OLMo): weights and data available, paper with most details (but not necessarily the rationale, failed experiments) Groeneveld+ 2024
- 最高程度的开放,不仅提供权重,还公开训练数据、代码和详细日志,允许社区完全复现和深入研究。
Course Components

Basic
Goal: get a basic version of the full pipeline working
Tokenization
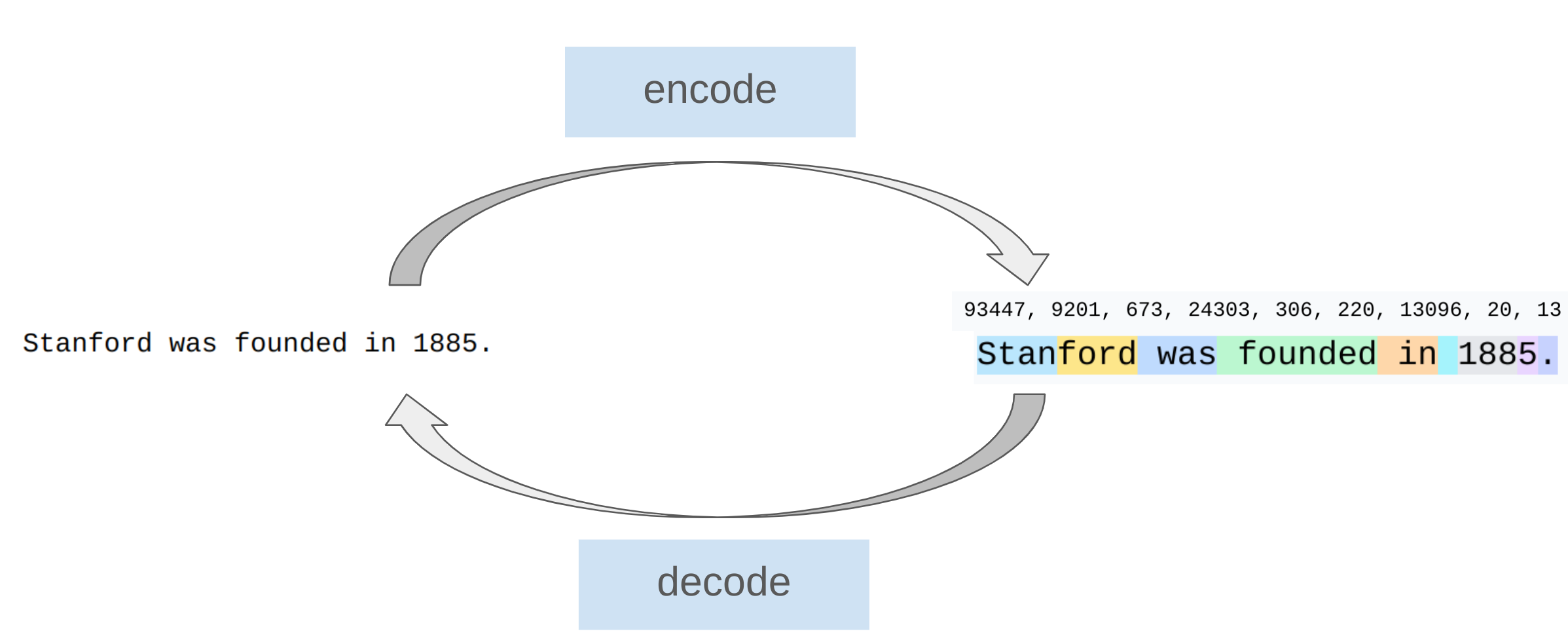
This course: Byte-Pair Encoding (BPE) tokenizer [Sennrich+ 2015]
Architecture
![]()
Scaling Law
Goal: do experiments at small scale, predict hyperparameters/loss at large scale
Question: given a FLOPs budget ($C$), use a bigger model ($N$) or train on more tokens ($D$)?
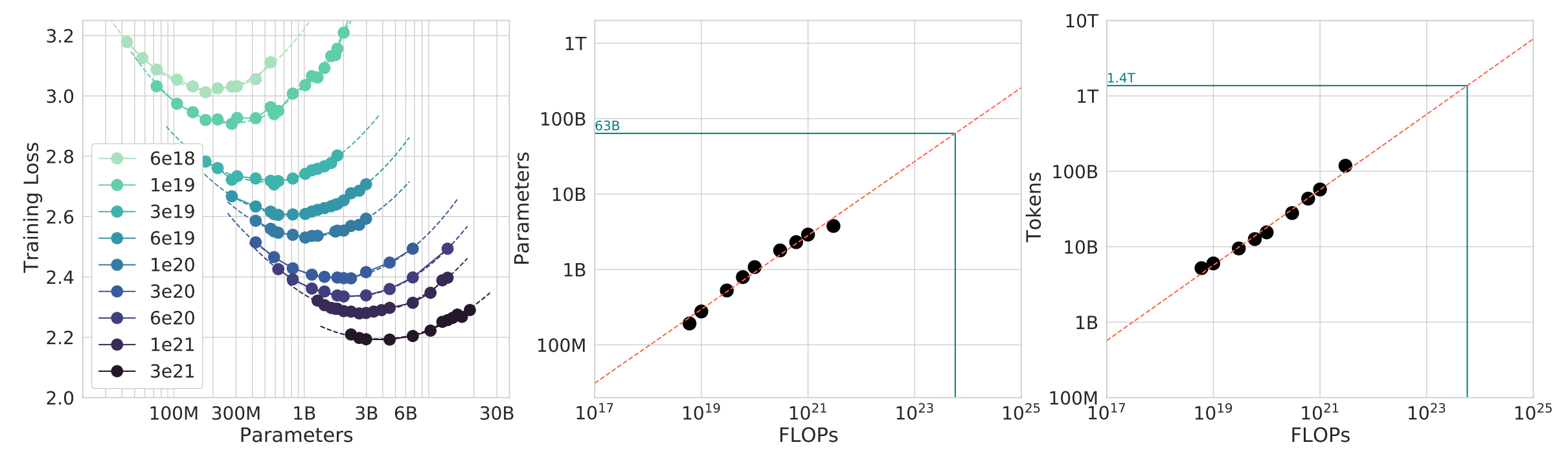
TL;DR: $D^* = 20 N^*$ (e.g., 1.4B parameter model should be trained on 28B tokens)
Data
Most of data on the Internet are trash!
CS336: Lecture 01 - Introduction
https://it-bill.github.io/blog/2025/cs336-lecture-01-introduction
作者 Bill
发布于 2025-12-05
更新于 2026-03-11
许可协议 CC BY 4.0
评论
B / U {}
0 条评论